When writing CSS for markup with weird class or id attribute values, you need to consider some rules. For example, you can’t just use ## { color: #f00; } to target the element with id="#". Instead, you’ll have to escape the weird characters (in this case, the second #). Doing so will cancel the meaning of special CSS characters in identifiers and allows you to refer to characters you cannot easily type out, like crazy Unicode symbols.
There are some other cases where you might want or need to escape a character in CSS. You could be writing a selector for a funky id, class, attribute or attribute value, for example; or maybe you want to insert some weird characters using the content property without changing your CSS file’s character encoding.
Identifiers and strings in CSS
Update @ March 2022: CSS identifier syntax has been changed to better align with HTML. The rest of this section is preserved here for historical reasons, and describes the old spec — not the latest spec!
The spec defines identifiers using a token diagram. They may contain the symbols from a to z, from A to Z, from 0 to 9, underscores (_), hyphens -, non-ASCII symbols or escape sequences for any symbol. They cannot start with a digit, or a hyphen (-) followed by a digit. Identifiers require at least one symbol (i.e. the empty string is not a valid identifier).
The grammar for identifiers is used for various things throughout the specification, including element names, class names, and IDs in selectors.
The spec definition for strings says that strings can either be written with double quotes or with single quotes. Double quotes cannot occur inside double quotes, unless escaped (e.g., as '\"' or as '\22'). The same goes for single quotes (e.g., "\'" or "\27"). A string cannot directly contain a newline. To include a newline in a string, use an escape sequence representing the line feed character (U+000A), such as "\A" or "\00000a". Newlines can also be represented as "\D \A " (CRLF), "\D " (i.e. \r in other languages), or "\C " (i.e. \f in other languages). It’s possible to break strings over several lines, for aesthetic or other reasons, but in such a case the newline itself has to be escaped with a backslash (\).
As you can see, character escapes are allowed in both identifiers and strings. So, let’s find out how these escape sequences work!
How to escape any character in CSS
Here’s a simple list of rules you should keep in mind when escaping a character in CSS. Keep in mind that if you’re writing a selector for a given classname or ID, the strict syntax for identifiers applies. If you’re using a (quoted) string in CSS, you’ll only ever need to escape quotes or newline characters.
Leading digits
If the first character of an identifier is numeric, you’ll need to escape it based on its Unicode code point. For example, the code point for the character 1 is U+0031, so you would escape it as \000031 or \31 .
Basically, to escape any numeric character, just prefix it with \3 and append a space character ( ). Yay Unicode!
Special characters in CSS
Any character that is not a hexadecimal digit, line feed, carriage return, or form feed can be escaped with a backslash to remove its special meaning.
The following characters have a special meaning in CSS: !, ", #, $, %, &, ', (, ), *, +, ,, -, ., /, :, ;, <, =, >, ?, @, [, \, ], ^, `, {, |, }, and ~.
There are two options if you want to use them. Either you use the Unicode code point — for example, the plus sign (+) is U+002B, so if you would want to use it in a CSS selector, you would escape it into \2b (note the space character at the end) or \00002b (using exactly six hexadecimal digits).
The second option is far more elegant though: just escape the character using a backslash (\), e.g. + would escape into \+.
Theoretically, the : character can be escaped as \:, but IE < 8 doesn’t recognize that escape sequence correctly. A workaround is to use \3A instead.
Whitespace characters
Whitespace — even some characters that are technically invalid in HTML attribute values — can be escaped as well.
Any characters matching [\t\n\v\f\r] need to be escaped based on their Unicode code points. The space character ( ) can simply be backslashed (\ ). Other whitespace characters don’t need to be escaped.
Underscores
CSS doesn’t require you to escape underscores (_) but if it appears at the start of an identifier, I’d recommend doing it anyway to prevent IE6 from ignoring the rule altogether.
Other Unicode characters
Other than that, characters that can’t possibly convey any meaning in CSS (e.g. ♥) can and should just be used unescaped.
In theory (as per the spec), any character can be escaped based on its Unicode code point as explained above (e.g. for 𝌆, the U+1D306 “tetragram for centre” symbol: \1d306 or \01d306), but older WebKit browsers don’t support this syntax for characters outside the BMP (fixed in April 2012).
Because of browser bugs, there is another (non-standard) way to escape these characters, namely by breaking them up in UTF-16 code units (e.g. \d834\df06 ), but this syntax (rightfully) isn’t supported in Gecko and Opera 12.
Since there is currently no way to escape non-BMP symbols in a cross-browser fashion without breaking backwards compatibility with older browsers, it’s best to just use these characters unescaped.
Trailing whitespace after hexadecimal escape sequences
Any U+0020 space characters immediately following a hexadecimal escape sequence are automatically consumed by the escape sequence. For example, to escape the text foo © bar, you would have to use foo \A9 bar, with two space characters following \A9. The first space character gets swallowed; only the second one is preserved.
The space character following a hexadecimal escape sequence can only be omitted if the next character is not another space character and not a hexadecimal digit. For example, foo©bar becomes foo\A9 bar, but foo©qux could be written as foo\A9qux.
Examples
Here are some random examples that illustrate this:
.\3A \`\( { } /* matches elements with class=":`(" */
.\31 a2b3c { } /* matches elements with class="1a2b3c" */
#\#fake-id {} /* matches the element with id="#fake-id" */
#-a-b-c- {} /* matches the element with id="-a-b-c-" */
#© { } /* matches the element with id="©" */For more, check out the demo page for the blog post on @id and @class in HTML5.
…and what about JavaScript?
In JavaScript, it depends.
document.getElementById() and similar functions like document.getElementsByClassName() can just use the unescaped attribute value, the way it’s used in the HTML. Of course, you would have to escape any quotes so that you still end up with a valid JavaScript string.
On the other hand, if you were to use these selectors with the Selectors API (i.e. document.querySelector() and document.querySelectorAll()) or libraries that rely on the same syntax (e.g. jQuery/Sizzle), you would have to take the escaped CSS selectors and escape them again. All you really have to do is double every backslash in the CSS selector (and of course escape the quotes, where necessary):
<!-- HTML -->
<p class=":`("></p>/* CSS */
.\3A \`\( { }/* JavaScript */
document.getElementsByClassName(':`(');
document.querySelectorAll('.\\3A \\`\\(');CSS escapes tool
Remembering all these rules sure sounds like fun, but to make life a little easier I created a simple CSS escaper tool that does all the hard work for you.
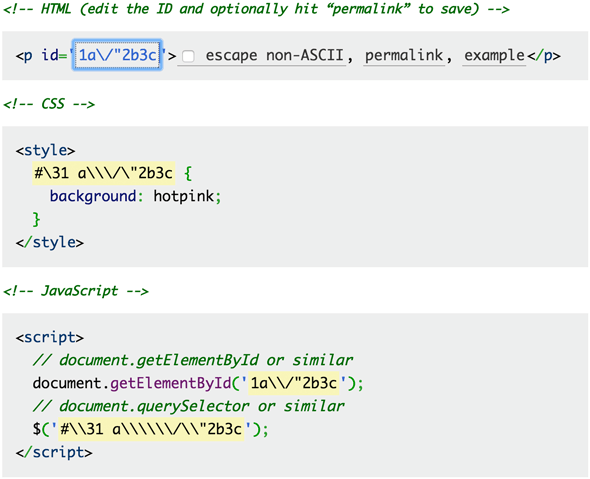
Just enter a value and it will tell you how to escape it in CSS and JavaScript, based on the rules above. It uses an id attribute in its example, but of course you could use the the same escaped string for class attribute values or the content property. Enjoy!
Need to escape text for use in CSS strings or identifiers? I’ve packaged the code that powers this tool as an open-source JavaScript library named cssesc. Check it out!
Update: The CSS Object Model spec now defines CSS.escape(), a utility method that performs the escaping for you. I’ve written a polyfill for it.
Note: If you liked reading about CSS escapes, why not read up on JavaScript character escape sequences or character references in HTML?
Comments
seutje wrote on :
I’ve already run into this nightmare as someone was using underscores in his class names and wasn’t escaping these in the CSS, which caused IE6 to completely ignore it, while all other browsers gladly accept it unescaped:
http://jsbin.com/esofe3 IE6 will show all green, all other browsers will show all red.Edit: Actually, only the unescaped
_foois a problem, notfoo_orfoo_bar. Here’s a better test case: http://jsbin.com/unogus Nice catch, Nicolas Gallagher!Steve wrote on :
As much as I appreciate the concept of this article I need to clarify something.
Setting the ID of an element to start with a number character "1,2,3,4,5,6,7,8,9,0" is not valid! Do not do it, ever. Using the above escape strings to work around it is hacking, and will get you in deep water quick.
More importantly there are SEVERAL scenarios that Microsoft took this spec rule to heart on and JavaScript WILL FAIL on if you try and access elements that are not created with a valid ID identifier.
I would HIGHLY, HIGHLY recommend using standard identifiers for all IDs… Start IDs with a “regular” alpha character, or underscore, and use alpha, numeric, underscore, or hyphen characters for the remainder of the identifier.
I can see no valid reason why one would need to create an ID in a format other than as described above… And if one decides to juggle hand grenades, do not be surprised when things blow up.
Mathias wrote on :
Steve:
You may want to read The
idattribute got moreclassy in HTML5. Spoiler: it was not valid in HTML4, but it has always worked in browsers, and HTML5 now allows it too.Care to give an example of where such an “invalid” ID would cause issues?
Steve wrote on :
Yup, so because IE has historical issues with IDs I will never try and use anything fancy, but here goes.
So IE has several bugs and one of the biggest is that it merges the ID and NAME attribute namespaces… Even up until IE8 calling
getElementById('someID');would actually return an element with a matchingnameattribute even though it had a differentid(or even no ID).Because of this “blurred” namespace, and IE’s attempts to “guess” what the developer intended, there are some major consequences.
Take for example a form that among other fields, contains a list of “items” that match records from a database that are in the form as a bunch of hidden fields with
IDs andNAMEs that use the “key” in the database..If you try to access these elements by say, using the FormElement’s elements collection like so:
This code looks like it will work, but it won’t in IE… The problem is that when IE is iterating over the elements collection of the form it is passed in a “key”… that key can either be the
NAMEof the element OR an index in the collection.When IE gets the string that we pass with the
NAMEof the element, IE doesn’t know which it is (nor does any browser), but IE decided that it would check to see if the value passed in parses to an integer first (i.e. an index). Then if it fails, tries it as aname. This fundamental flaw means that if yourNAME(orIDattribute because of the namespace bug) starts with a number (which is against the spec) when parsed as an integer… returns[739]which IE then says to itself, “oh, I have an index now — I’ll go look up by index” but alas your form does not contain738(zero-indexed) elements, thus throws an error (or quietly swallows it) that it can’t find the field (Array Index Out Of Bounds Exception).The solution of course is simple… Just follow the original spec, and name the elements
item739.There’s several more issues… but after doing web application development for 12+ years I quickly learned to NOT use IDs or NAMEs that start numbers. It will fail… it’s just a matter of when.
P.S. At one point I discussed the above bug with Chris Wilson (ex-Chief Architect of IE) and was pointed to the specs. Basically it was a “yes this is buggy in IE, but using
IDs orNAMEs that start numeric is against the spec, so we are not fixing it”.Steve
Mathias wrote on :
Steve: You make a fair point — there can be issues when using such IDs (edge case) combined with edge case DOM methods and accessors. However, I don’t see why you would jump through such hoops just to select an element based on its ID. Simply using
document.getElementById('145item')would work fine in your example.Diego Perini wrote on :
Mathias: Another issue with IDs like
145itemis you cannot target elements with CSS using ID selectors starting with a digit. Maybe some selector engine will allow that but as underlined by Steve “it is against the CSS specs”.Mathias wrote on :
Diego: Yeah, that’s what I tried to explain in this blog post.
#145itemis an invalid selector as145itemisn’t a valid CSS identifier. In order to make it work, you have to use valid CSS, for example by escaping the identifier properly, which is what this blog post is all about.Diego Perini wrote on :
Yep :) You are right, I should have read first, I didn't realize I was in a post I already visited in the past. This is the product of following links in searches and just reading the last two post before answering. Not proud of that, your patience is appreciated :9)
Taylor Hunt wrote on :
Mathias: This is a couple years later, of course, but I did just run into this very issue with the latest production version of Chrome, and thought you might be interested. I was doing some styling with the
:targetpseudo-class, and IDs named#1,#2,#3, etc. refused to work with it. Renaming them to letters fixed the problem.Olivier C wrote on :
Example for class:
…with the selector
[class*=""]:And it works…
Mathias wrote on :
Olivier: In that example, you’re using a string rather than an identifier.
MR wrote on :
Steve: The regex for that pseudo-regex is:
^([a-zA-Z])([_\-a-zA-Z0-9])*$.